论文原文: http://nil.csail.mit.edu/6.5840/2024/papers/zookeeper.pdf
中文译文: https://github.com/mapleFU/zookeeper_paper_cn
定义
ZooKeeper 提供了一系列简单,高性能的原语用于协调不同的分布式系统。它在多副本、中心化的服务中,组合了消息群发(_group messaging_), 共享寄存器(_shared registers_)和分布式锁(D_istributed Lock_)服务。
Introduction
大规模的分布式应用需要不同形式的协调。比如配置发现,某个分布式系统写入了一个多个分布式系统之间共享的一个配置,需要有一个协调者去 notify 使用这组配置的分布式系统配置变更,并且为了不因为某一小部分而影响整个大型分布式系统的 fault tolerance,配置也必须是存储在分布式存储上的。既然存在写入,那也必然会存在并发写入的情况,这个时候就需要分布式锁保证资源的互斥访问。
ZooKeeper 在设计时并没有直接在服务端侧实现互斥锁一类特定的原语,相对的 ZooKeeper 暴露了一系列相对基础的 API,让用户可以更自由的进行分布式系统之间的协调。ZooKeeper API 的设计在服务端侧都是 wait-free 的,这使得 ZooKeeper 可以接受请求的吞吐量巨大。并且 ZooKeeper 确保了针对单个客户端请求的线性一致性,即请求的执行一定是按照收到请求的时间顺序来的,这使得对 ZooKeeper API 的原语进行组合从而得到一个更加强大的原语(比如互斥锁)成为了可能。
Zookeeper 使用 Zab(Zookeeper atomic broadcast) 协议(基于 Paxos)在分布式环境中达成共识。
Coordination kernel: 我们提出了一种 wait-free 的协调服务,可用于在分布式系统中提供宽松的(_relaxed_)一致性保证。特别是,我们描述了_协调内核_的设计和实现,我们已经在许多关键应用程序中使用了协调内核来实现各种协调技术。
Coordination recipes: 我们展示了如何使用 ZooKeeper 在分布式系统中构建高级协调原语,甚至是常用的阻塞和强一致性原语
Experience with Coordination: 我们分享了一些我们使用 ZooKeeper 的方式,并评估其性能。
The ZooKeeper Service
Service Overview
ZooKeeper 给它的客户端提供 znodes 的抽象,这些数据节点通过分层的命名空间(比如 /A/B/C,类似 unix file system)来组织。客户端通过 ZooKeeper API 操纵在这个层级中的数据对象。
客户端可以创建两种节点:
常规节点(
Regular): 可以创建或删除;临时节点(
Ephemeral): 临时节点,可以被显式删除,要么在创建它们的 session 终止时自动删除。
此外,当客户端创建新的
znode的时候,可以设置 sequential 标志。带有 sequential 标志创建的节点会在节点名称后附加一个单调递增的计数器的值。如果 n 是新的 znode, p 是 n 的父节点,那么 n 的附加值不会小于 p 已有子节点的任何一个附加值。
ZooKeeper 通过 watch 来让客户端不需要轮询就可以感知到数据变化,客户端在读取节点时可以设置 watch flag 为 true,这样当节点数据产生变化时便会收到通知,但通知中并不包含节点数据变化的具体内容,需要客户端侧再次发起请求获取数据。Watches 是与会话关联的一次性触发器, 一旦被触发或者该会话关闭,它们将被注销。
ZooKeeper 的数据模型本质上是一个简化了API的文件系统,只支持完整数据的读写,或者可以说是一个带有层级式 key 的 key/value 表。分层命名空间便于为不同应用的命名空间分配子树,也便于为这些子树设置访问权限。
上图中,app1 实现了一个简单的组成员身份协议(group membership protocol):每个客户端进程(即客户端分布式系统的单个节点)pi在/app1下创建一个znodep_i,只要该进程还在运行,节点便会持续存在,这个设计是基于临时节点实现的。
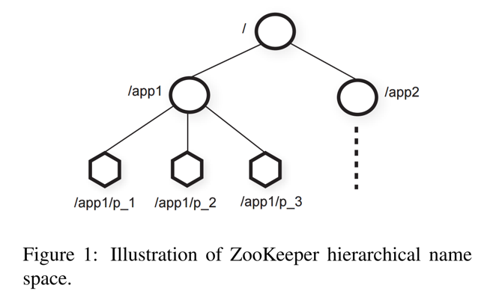
尽管 znode 并非为通用数据存储设计,但是 ZooKeeper 允许客户端存储一些可用于分布式计算中的元数据或配置的信息。
sessions
客户端连接到 ZooKeeper 会初始化一个 session,session 有一个超时时间,一旦在超时时间内没有收到来自 session 的任何信息,则会断开 session。相同的 session 也可以在不同机器之间迁移(比如 k8s 中服务迁移到不同的容器,仍然可以继承相同的 session)。
Client API
create(path, data, flags): 根据路径名称path,它存储的data[],创建一个znode, 并返回这个新的znode的名称。flags允许客户端选择选定的znode类型:regular,ephemeral及设置sequentialflag。
delete(path, version): 如果znode符合给定的version版本,则删除path下的znode。
exists(path, watch): 如果path下的znode存在,返回 true, 否则返回 false.watch标志可以使 client 在znode上设置 watch。
getData(path, watch): 返回znode的数据和 znode 相关的元数据(例如版本信息)。watch和exists()里面的作用一样,不同之处在于,如果znode不存在,则 ZooKeeper 不会设置watch。
setData(path, data, version): 如果version是znode现有的版本,把data[]写进znode.
getChildren(path, watch): 返回path对应的znode的子节点集合。
sync(path): 等待操作开始时所有没有同步的更新传播到 client 连接到的服务器。 该path当前被忽略。
ZooKeeper guarantees
Linearizable Writes: 所有的更新 ZooKeeper 状态的请求都是可序列化的(_serializable_),并且遵循优先级。
FIFO client order: 给定客户端发送的所有请求都按照客户端发送顺序有序执行。
Examples of primetives
Simple locks
客户端首先使用 exists 检查指定路径是否存在节点,如果不存在,创建一个临时的 znode 。这一操作相当于获取了锁,再有其他客户端使用 exists 发现路径有节点就说明锁被占用,在 znode 被删除即锁被释放时会通过 watch 机制唤醒等待这个锁的其他客户端,但唤醒太多客户端会引发锁的争抢。
Simple locks without Herd Effects
为了避免锁的争抢,对锁作出下面的改进:
1 | Lock |
这样相当于利用 SEQUENTIAL 机制提供的分布式计数器实现了一个阻塞队列,每次只会唤醒队列头部的节点获得锁。
Read/Write Locks
1 | Write Lock: |
读锁跟读锁不互斥,写锁跟读锁和写锁互斥
Double Barrier
类似 java 的 count down latch ,go 的 wait group。
double barriers 使 client 能够同步计算的开始和结束。当有足够多的进程(具体数量由 barrier 阈值决定)进入到 barrier 中时,进程将会开始它们的计算,并在计算结束后离开 barrier。我们在 ZooKeeper 中用
znode表示一个 barrier,称为_b_。 每个进程p都会在进入时通过将znode创建为 b 的子节点来向 b 注册,并在准备离开时注销,即删除该子节点。 当b的子znode数量超过 barrier 阈值时,进程可以进入 barrier。 当所有进程都删除了其子进程时,进程可以离开 barrier。 我们使用 watch 来有效地等待进入和退出 barrier 条件得到满足。 要进入 barrier,流程会监视是否存在 b 的 ready 子znode,该子znode将由导致子节点数超过障碍阈值的进程创建。 要离开 barrier,进程会 watch 特定的子节点的消失,并且仅在这个znode被删除之后检查退出条件。
ZooKeeper Application
论文中给出的是还没捐给 apache 时期的一些雅虎内部服务
这里列出一些日常比较常用的
Apache Kafka - 分布式发布/订阅平台
- 存储配置,节点注册信息和topics
- 选举 Controller
- 存储配置,节点注册信息和topics
Apache Hadoop - 分布式数据处理框架
- HDFS 选举/故障转移
- 分布式锁
- HDFS 选举/故障转移
Apache HBase - NoSQL数据库
- 存储 meta 表的地址
- 选举 Master
- Region Server 注册与发现
- 存储 meta 表的地址
Apache Flink - 分布式实时计算系统
- 存储计算拓扑的元数据、状态和节点信息
- 任务分配和协调
- 选举 Master
- 存储计算拓扑的元数据、状态和节点信息
ZooKeeper Implementation
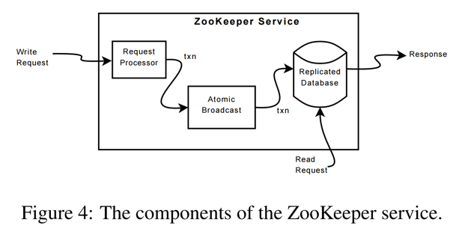
ZooKeeper 通过复制状态机(replicated state machine)来实现高可用性。如上图,收到写请求时会使用 agreement protocol 保证写入数据在 replicated database 中已经完全复制。
replicated database 是一个包含整个数据树的内存数据库,一般来说单个节点存储数据不超过 1MB(这是可配的)。并且为了可恢复性,强制在写入内存之前先写入磁盘(write ahead log)。并周期性的做 log compaction(生成 snapshot)。
写请求会被转发给 leader,再由 leader 广播给所有 follower,follower 从 leader 那里接受包含状态变更的 proposal,达成一致。
Request Processor
因为 message layer 是 atomic 的,我们保证副本不会出现分歧,尽管在任意时刻,某些服务器可能会应用了比其他服务器更多的事务。与客户端的请求不同,事务是幂等的。领导者收到写请求后,它将计算_应用_写操作时系统的状态,并将其转换为捕获该新状态的事务。 因为可能存在尚未应用到数据库的未完成事务,所以必须计算未来的状态。 例如,如果客户端执行条件
setData,并且请求中的版本号与正在更新的znode的未来的版本号匹配,则该服务将生成一个setDataTXN,其中包含新数据,新版本号和更新的时间戳。 如果发生错误,例如版本号不匹配或要更新的znode不存在,则会生成errorTXN。
Atomic Broadcast
所有写请求都会被转发给 leader,再由 leader 使用 Zab 原子广播协议广播给其他 follower。Zab 使用 majority quorum 来决定一个 proposal。
ZooKeeper 为了高吞吐量对请求做了流水线化,由于状态变更依赖于上一个状态,所以 Zab 协议提供了一个顺序保证。
有一些可以简化实现的细节,比如可以使用 TCP 来让网络层保证消息顺序。
消息只要按顺序 deliver,就可以多次 deliver,因为使用了幂等事务。
Replicated Database
- Replicated database 生成 fuzz snapshot,也就是不上锁,深度优先遍历整个树并原子的读节点的值得到快照。由于 zookeeper 的状态是幂等的,只要按状态应用的顺序进行 apply log,最后会得到一致的结果。
- 也就是说 snapshot 的值不一定代表当时的状态,但是只要将剩余的日志全部 apply 就可以得到正确的状态,也就是说没有办法像 mvcc 一样做 time travel,也不需要像 write ahead log 的 recovery 一样先进行 undo,这就是幂等性带来的好处。
Client-Server Interactions
即便针对某个节点的写操作已经被 commit,但是读操作仍然有可能读不到这个值,所以有了 sync,sync 保证在它之前的所有操作被应用,sync 这一操作只需要在 leader 上实施,所以不需要广播给 follower。