MIT 6.s081 lecture 17 个人总结笔记
参考:
之前我们知道,virtual memory 的 page fault 已经被内核玩出了花。进程 fork 的 COW 机制,虚拟内存页表的驱除机制等等,都是利用了 page fault 这个机制实现的。page fault 很好用,那么我们能不能让用户程序也利用上 page fault 呢?
为了让用户程序有效的利用上 page fault 机制,操作系统内核需要向用户程序提供一系列原语(primitives):
Prot1 降低单个 page 的 accessibility (mprotect)
ProtN 降低 N 个 page 的 accessibility,之所以单独提出是因为保护多个 page 的平均开销更小 (只需要刷新一次 TLB)(mprotect)
Unprot 解除单个 page 的保护 (mprotect)
Dirty 查看一个 page 是否为 dirty page
map2 使得一个应用程序可以将一个特定的物理内存地址空间映射两次,并且这两次映射拥有不同的accessability (mmap)
有了这些原语,用户程序就可以利用 page fault 的机制做一些更好的优化。
eg.1 构建大的缓存表
我们可以用设计虚拟内存驱除机制的思路,利用上面提到的操作系统提供的一系列原语使用有限的虚拟内存构建一个非常大的缓存表。
下面提供一个比较极端的代码示例——只使用一页虚拟内存实现的缓存表
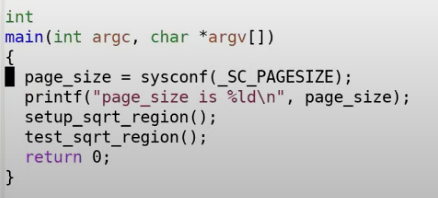
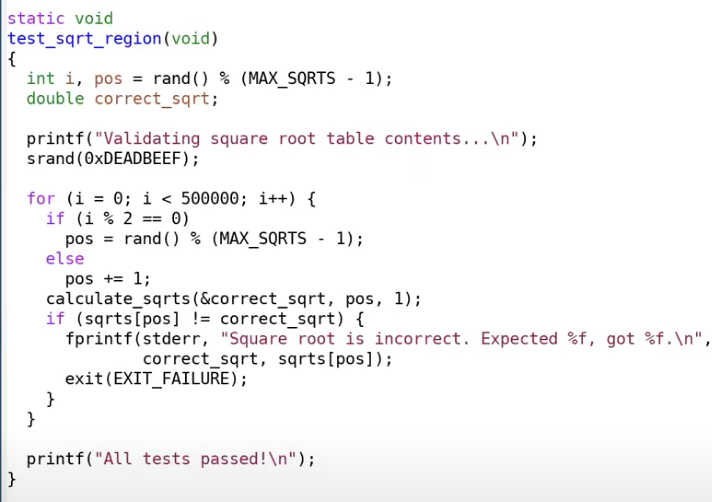
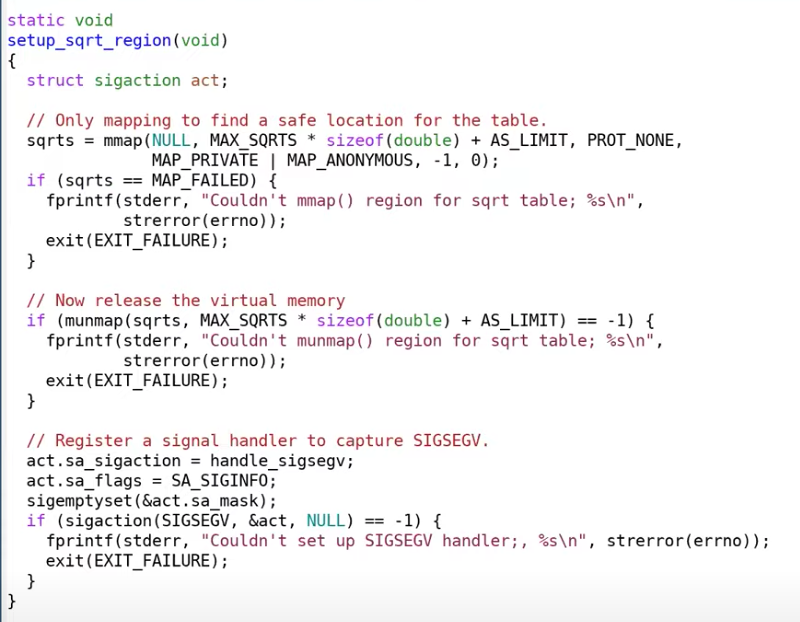
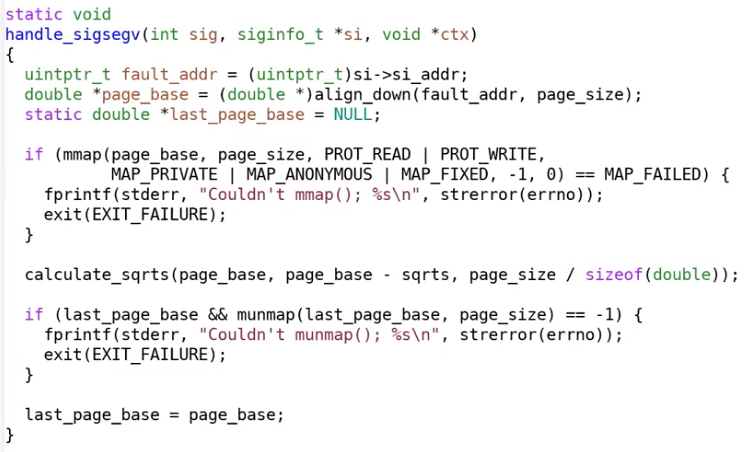
eg.2 Baker’s Real-Time Copying Garbage Collector
以前背过一些关于 GC 的 Java 八股文,没想到会在这里再接触到这个话题
我们先讨论一种特定的 copying GC,假设你有一段内存作为heap,应用程序从其中申请内存。你将这段内存分为两个空间,其中一个是from空间,另一个是to空间。Copying GC 的基本思想是将仍然在使用的对象从 from 空间复制到 to 空间。在 to 空间满时进行翻转。至于如何识别对象是否在使用可以使用可达性分析算法。
背过 java 八股文的人就知道,我们希望尽可能缩短 copy 所花的时间,因为这段时间我们需要 stop the world。那么我们可不可以将 copy 所花费的时间成本均摊一下,不让程序触发 GC 后突兀的停顿很长一段时间?
我们可以使用设计 COW 的思路来做这件事,触发 GC 时我们只 copy GC root,将时间成本降到最低。然后我们将 GC root 标记为 unscanned (使用 prot 原语降低其可见性),在我们下次访问 GC root 时就会触发 page fault,进入到我们设置的 page fault handler。在 page fault handler 中将当前页中的地址指向的页也 copy 到 to space,对指针进行 forwarding (就是将指针的指向从原本在 from space 的内存转发到 to space 的内存),并且将其标记为 unscanned。然后我们将扫描过的页标记为 scanned(也就是对其进行 unprot 操作)。这样我们就成功的将 GC 的时间成本分摊到了程序读写虚拟内存的时候。
但是既然用户程序不能访问,访问了会导致 page fault,那 GC 线程要怎么访问呢?当然我们可以在 page fault handler 中使用 unprot 操作,但是这样做的话会导致并发的问题(在 GC 线程 unprot 后其他用户线程访问了这块内存)。所以我们需要 map2 原语,将一块物理内存映射到两块虚拟内存地址,一块供 GC 线程读写(可读写),一块供用户线程读写(unscanned的情况下不可读写)。这样便完美的解决了这个问题,同时我们获得了天然的并发性:因为 unscanned 状态下 GC 线程读写内存时用户线程无法读写这块内存内存,而 scanned 状态下用户线程读写内存时 GC 线程不会读写这块内存。