https://zhuanlan.zhihu.com/p/208680604
在本文中,我们首先介绍了以下三个贡献:
如何在云规模上实现可持久性,以及如何设计Quorum系统来应对关联故障。(第二节)
如何将传统数据库的下层部分转移到存储层实现智能存储。(第三节)
如何在分布式存储中移除多阶段同步、崩溃恢复以及Checkpoint。(第四节)
Persistence
Quorum
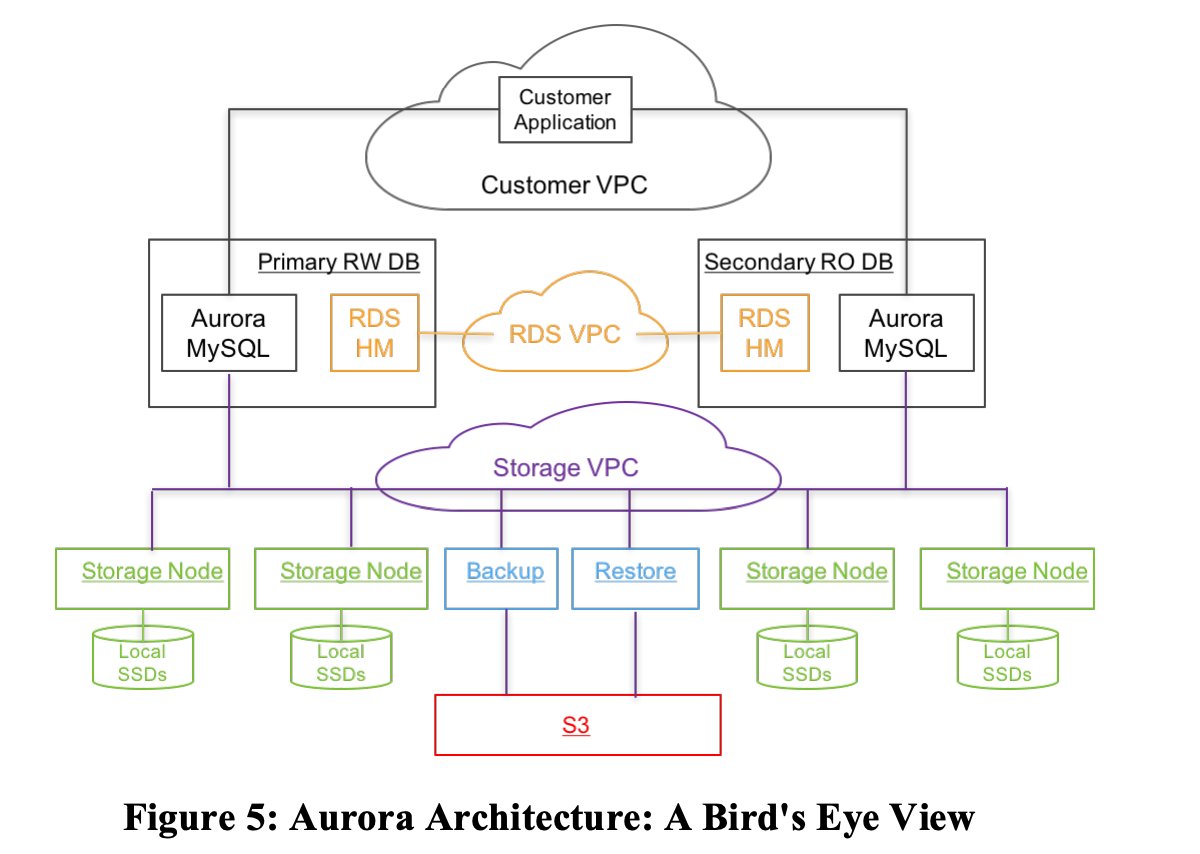
Aurora 使用复制状态机来保证容错,并且设计了一种基于 Quorum 的投票协议来控制读写,提供一定程度的一致性保证。
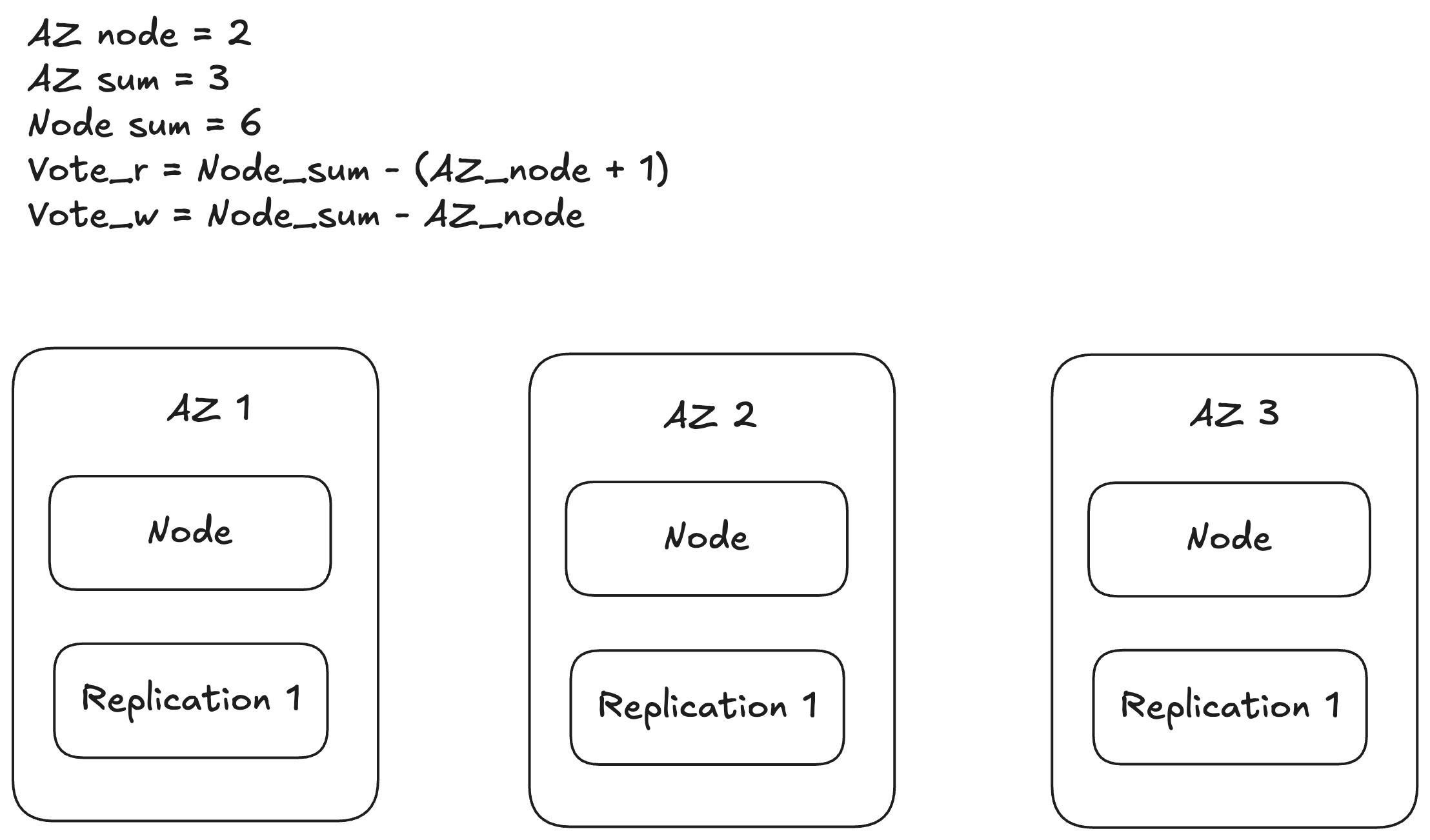
在 Aurora 中,允许在整个 AZ 故障再加一个节点故障的情况下读,也就是在有 3 个 AZ ,一个每个 AZ 内有两个 replication node 的情况下(这也是 amazon aurora 的默认设置,每份数据会被复制 6 份),获得 2 * 3 - 2 - 1 = 3 票即可进行读操作。而写操作则只能容忍单个 AZ 故障,也就是需要 2 * 3 - 2 = 4 票。
这个设计让整个 AZ 瘫痪再加一额外节点故障的情况下能够保证读可用性,确保读Quorum使我们能够通过添加其他附加副本拷贝来重建写Quorum。
AZ是一个地域的子集,与该区域其他的AZ通过低延迟连接,但是AZ之间的大多数故障是隔离的,包括电源、网络、软件部署、洪灾等。将数据副本分布在不同的AZ中,可确保大规模系统中的典型故障只影响一个数据副本。这意味着只要简单地将这三个副本放在不同的AZ中,就可以应对除了较小的单个故障之外的大规模事件。
分段
这个设计的可用性取决于发生双重故障的概率,如果有两个 AZ 同时挂掉了,那么就会进入完全不可用的状态。降低这种情况发生的概率有两种办法,一种是降低 MTTF - 平均故障时间,另一种是降低 MTTR - 平均修复时间。amazon的工程师在实践中发现 MTTF 是很难降低的,所以可以从降低 MTTR 入手:将数据分为 10 GB 的段,分散在 3 个 AZ 中 6 个节点中。在10Gbps的网络连接条件下,一个10G的数据段可以在10秒内被修复,而在这 10s 单个数据段同时发生故障的情况就会变得非常小。
基于 Fault Tolerance 的运营玩法
一旦一个系统设计成对长期故障具有可恢复性,那么应对短期故障也就不在话下。一个可以处理AZ长期失联的存储系统,同样也可以处理由于电源事件或需要回滚的异常软件部署造成的短暂中断。一个可以处理几秒钟成员失联的Quorum,同样也可以处理短暂的网络拥塞或存储节点的高负载。
由于我们的系统对故障的容忍度很高,因此我们可以通过这一点来进行由于数据段不可用的运维操作。举例来说,热点管理可以变得很简单。我们可以将热点磁盘或节点上的某个数据段标记为故障,那么通过迁移系统中的其他非热点节点,Quorum就可以被快速修复。操作系统和安全补丁在进行修复时,对于存储节点来说是一个短暂的不可用事件。甚至软件更新也可以通过这种方式来进行管理。只需要一次执行一个AZ,并确保同一个PG内没有两个成员同时被处理即可。基于这些,我们可以在存储服务上使用敏捷方法和快速部署。
利用人为标记故障来做热点管理,补丁热修复,软件更新,很让人脑洞大开的玩法,这也得益于 Aurora 强大的容错和快速恢复。
日志即DB
由于每个段都被拷贝了 6 份组了 4/6 Quorum,所以在高 IO 的场景下很容易写放大从而导致写入卡顿,延迟增大。
像 MySQL 这样的传统 DB 一般都是先将 REDO log 写入磁盘(WAL),然后写入实际内容,这样即便在写入过程中 crash 也可以通过 REDO log 恢复数据。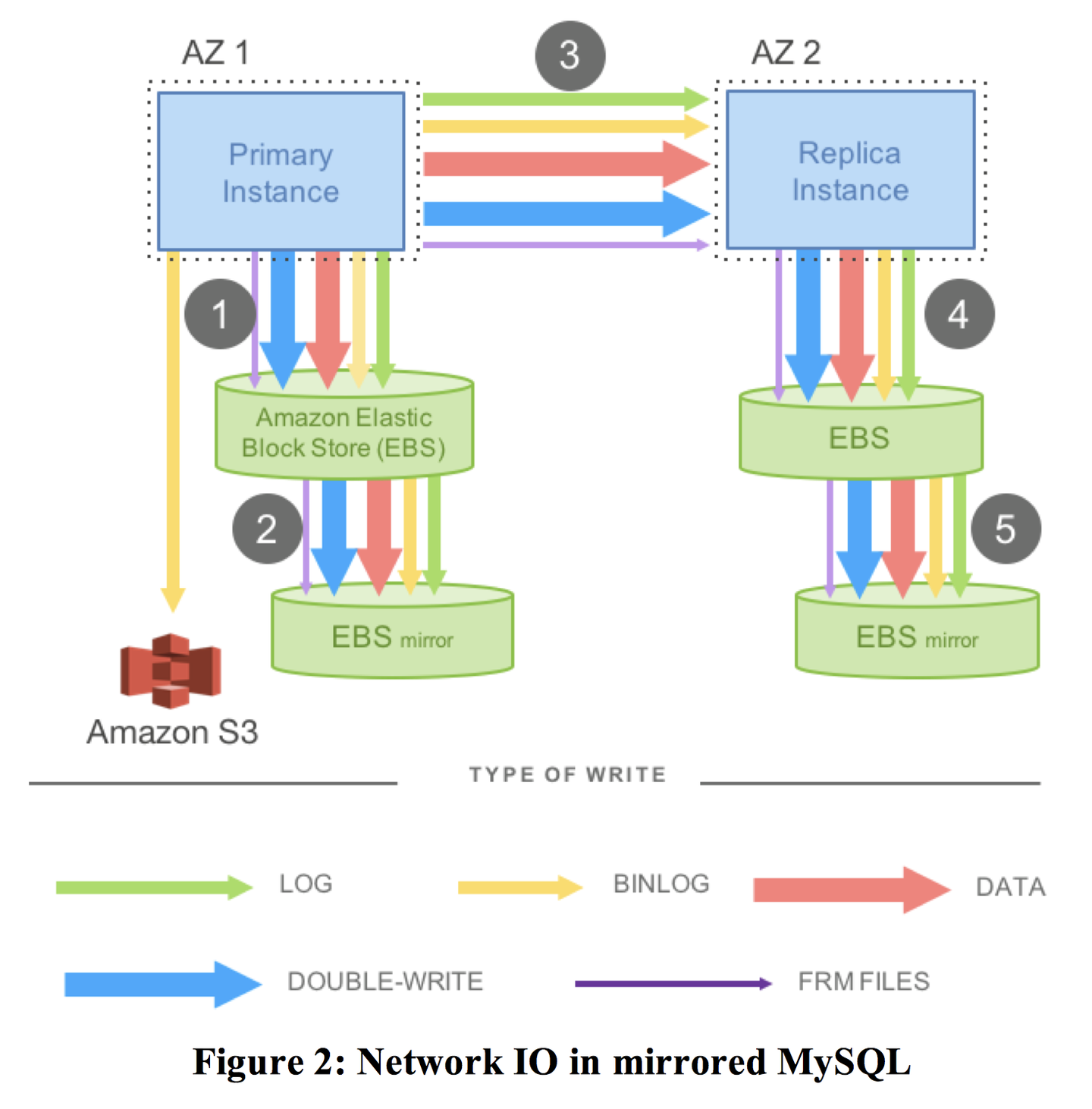
既然如此,我们完全可以把 REDO log 的写入迁移到存储层。存储层之间只通过网络传递 REDO log,而不是整个的段/块,这样就大大减少了网络 IO。而在单次写入操作中一旦满足了 4/6 Quorum,则视为该日志已经被提交,节点将会将该日志的内容写入内部存储。
并且 Aurora 的 crash recovery 跟传统数据库不同,不需要一来就恢复数据,而是可以将恢复数据这一操作分散到前台的读操作,这也加快了恢复速度,降低了 MTTR,提高了可用性。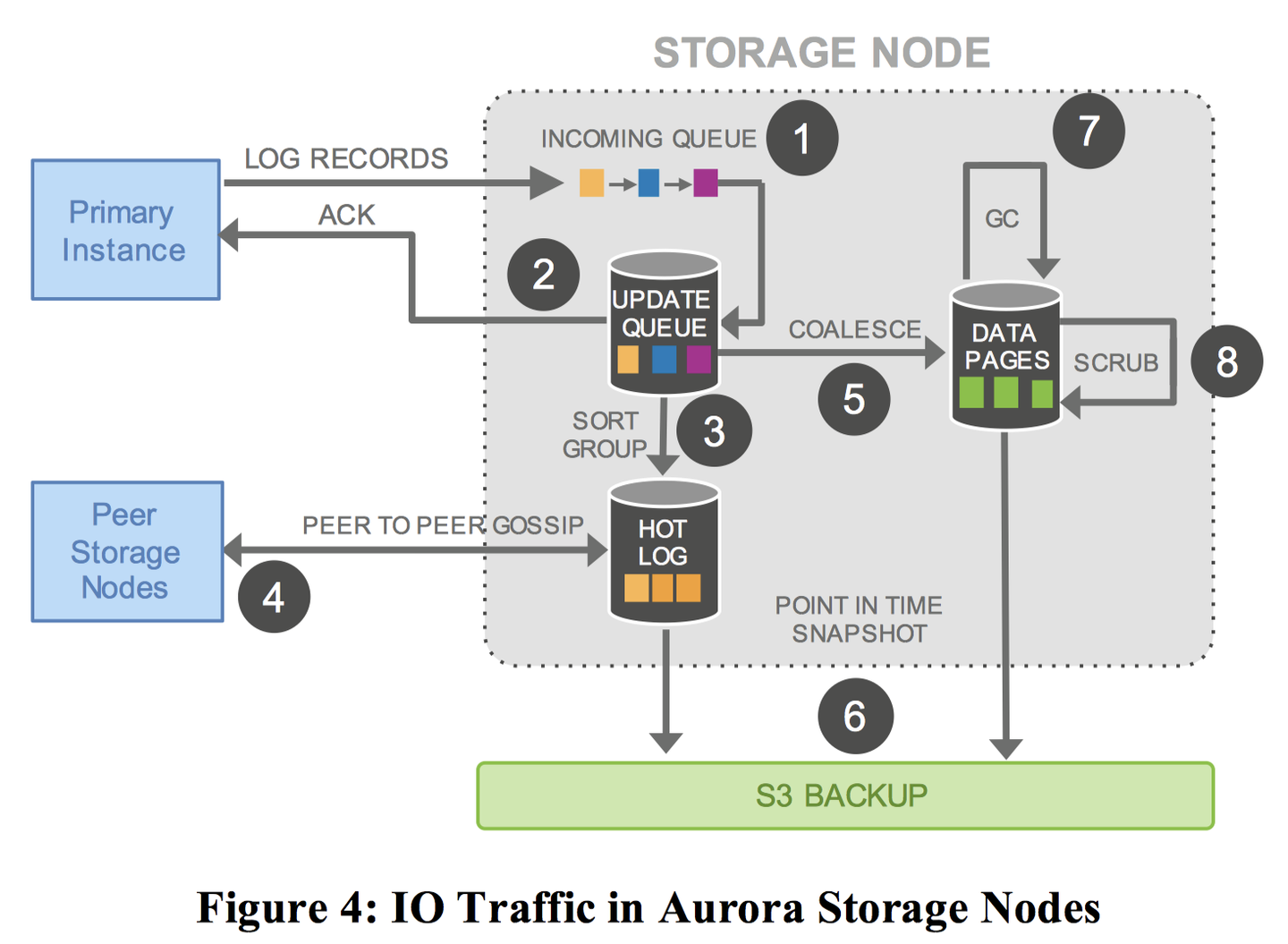
日志驱动
事务
在 Aurora 中上层数据库的操作被看作一个日志流,每个操作都会生成一条日志,并附带一个单调递增的日志序列号(LSN)。这样做的好处是不需要使用 2PC 这种复杂的协议来实现分布式事务,并且单个节点崩溃后可以通过 LSN 快速从其他节点中同步状态并恢复一致。
Consistency Point LSN(CPL):表示在某个特定的 LSN 上,数据库级别的数据是完全一致的,不存在部分提交或不完整的数据。(其实也就是 checkpoint)
Volume Durable LSN (VDL):这是卷级别的 Checkpoint,Aurora 认为小于 VDL 的 LSN 都已经被持久化。
- 每个数据库级别的事务被拆分为多个有序的微事务(MTR),且必须被原子的执行。(这意味着这一段日志中间不能插入其他(相同段的)日志)
- 每个微事务都由多个连续的日志记录组成。
- 微事务的最终日志记录是一个CPL。
日志按PG分组(Protection Groups),每个PG 10GB
不需要2PC,容灾和故障恢复直接复制PG
写入
在写每个日志的写 Quorum 建立后则会将 VDL + 1,这代表日志已经在大部分节点写入。
提交
VDL >= LSN 时则认为这条日志已经被提交。
读取
正常情况下不需要建立读 Quorum,数据库会根据 VDL 选择一个数据相对完整的节点进行读取。
Aurora数据库不会在逐出数据页时写磁盘,但它会做出类似的保证:缓存中的数据页必须始终是最新版本。这个保证通过仅当数据页是“页LSN”(标识与页面的最新更改相关联的日志记录)大于等于VDL时,将其从缓存中逐出数据页来实现。该协议可确保:(a) 所有页面的修改都被持久化到日志中,并且(b) 在缓存未命中时,从当前VDL开始请求页面的版本以获取最新的持久化版本就足够了。
恢复
故障恢复直接复制 Partition Group 的 log,所以很快。
Putting it all together